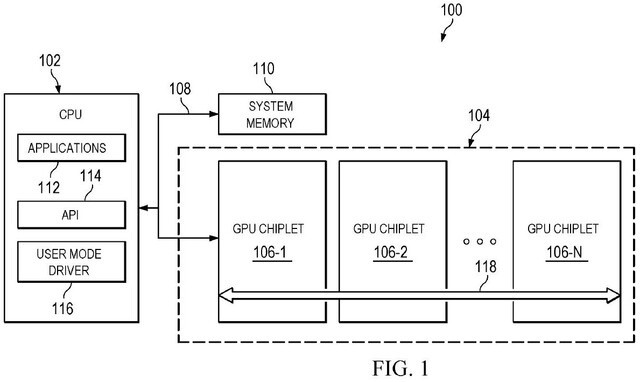
AMD最近公布了一项专利,在多个GPU芯片组之间分配渲染负载。通过这种方式,游戏场景将被划分为单独的块,并分配给小芯片,以优化游戏中着色器的利用。AMD公布的新专利为该公司在未来几年使用下一代GPU和CPU技术打开了更多的思路。
 游戏中的着色器" />
游戏中的着色器" />
截至6月底,AMD披露了54项专利申请。目前公布的50多项专利中,AMD的计划会利用哪一项还不得而知。专利中讨论的申请详细说明了该公司未来几年的实践。
成员@ETI1120注意到ComputerBase网站上的一个申请,专利号US20220207827,里面讨论了关键图像数据要分两个阶段,来自GPU的渲染负载可以有效的转移到很多小芯片上。CPU技术于去年年底首次应用于美国专利局。
 游戏中的着色器" />
游戏中的着色器" />
当GPU上的图像数据通过标准方式光栅化时,着色器单元(也称为ALU)将执行相同的任务,并将颜色名称分配给单个像素。相反,在特定游戏场景中的特定像素处发现的纹理多边形被直接映射到像素上。最后,公式化的任务将保持非典型原则,仅通过位于不同像素的其他纹理来区分。这种方法被称为SIMD,即单指令多数据。
对于目前大多数游戏来说,着色并不是GPU承担的唯一任务。相反,在初始着色之后,包括几个后续的加工步骤。比如GPU会添加的动作有游戏环境的反走样、阴影、遮挡等。但是光线追踪是和着色同时进行的,创造了一种新的计算方法。
 游戏中的着色器" />
游戏中的着色器" />
当GPU控制和处理当前游戏中的图形时,计算机产生的负载会成倍增加到上千个计算单元。
在GPU处理的游戏中,这种计算负载以一种相对理想的方式扩展到上千个计算单元。这与处理器不同,因为必须专门编写应用程序来添加更多的核心处理。CPUscheduler创建了这个动作,它将来自GPU的工作分成更容易分解的任务,并将它们提供给计算单元进行处理。这就叫分级。游戏中的图像被渲染,然后分成独立的块,这些块包含一定数量的像素。该块由图形处理器的子单元计算,然后在那里同步和创建。这个动作之后,等待计算的像素被包含在一个块中,直到显卡的子单元最终被使用。AMD在设计过程中考虑了着色器的计算能力、内存带宽和缓存大小。
AMD在专利中解释说,GPU不同步骤之间的划分和连接需要一个彻底完整的数据连接,这就带来了一个问题。不在芯片上的数据链路延迟较高,导致处理速度较慢。
CPU毫不费力地实现了向芯片的这种过渡,因为它可以同时在几个核心上发送任务,使其可供芯片使用。GPU不提供同样的灵活性,它的调度器只能和入门级双核处理器相提并论。
 游戏中的着色器" />
游戏中的着色器" />
 游戏中的着色器" />
游戏中的着色器" />
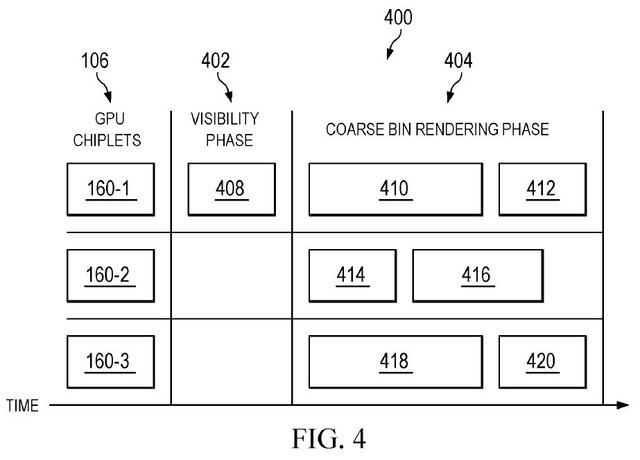
AMD意识到了这一需求,并试图通过改变光栅化流水线,在几个GPU小芯片之间发送任务来解决这些问题,类似于CPU。这需要先进的分层技术,公司正在引入“两级分层”,也就是所谓的“混合分层”。分层被处理成两个独立的阶段,而不是直接处理成逐像素的块。第一步,计算方程,取相应的三维环境,从原始图像创建二维图像。这个阶段称为顶点着色,在光栅化之前完成。这个过程在GPU的第一块芯片上比较短。一旦完成,游戏场景就开始分级,交给不同的芯片处理。然后,光栅化和后处理等常规任务就可以开始了。
