在HotChips34大会上,英特尔公布了PonteVecchioGPU高性能计算卡的更多细节,包括性能数据。
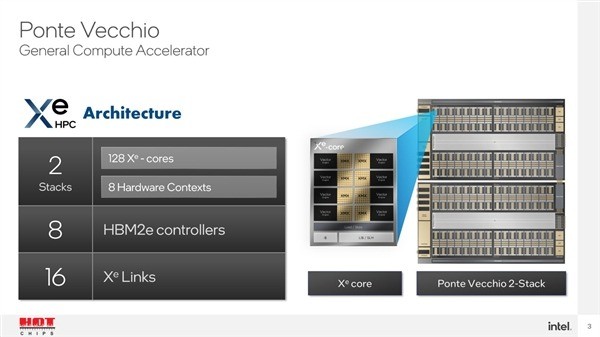
PonvecchioGPU基于全新XeHPC高性能计算架构,采用五种不同的制造工艺(英特尔7和TSMCN7/N5等。)和各种封装技术,集成了多达47个不同的计算模块,超过1000亿个晶体管。
它在一个模块中拥有128个Xe内核、128个光学追逐单元、64MBL1高速缓存、408MBL2高速缓存和128GBHBM2e高带宽内存。它支持PCIe5.0,可以四路甚至八路并联。



英特尔给出的最新数据声称,庞特
VecchioFP32单精度和FP64双精度性能可达52TFlops,TF3.2浮点性能可达419TFlops,BF16和PF16浮点性能可达839TFlops,INT8整数性能可达1678Tops。
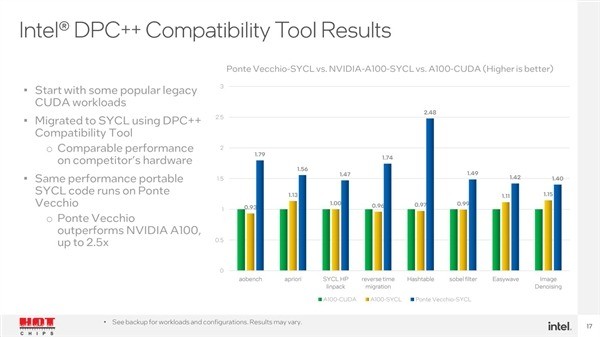
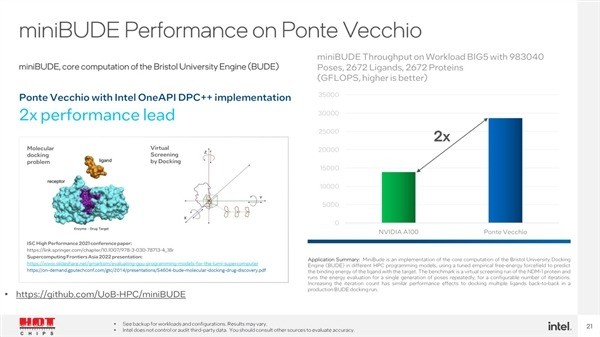
在数据并行C(DPC)测试项目中,PonteVecchio的性能可以领先NVIDIAA1001.4-2.5倍。
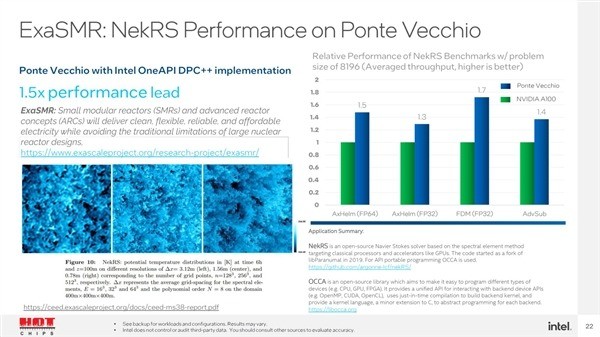
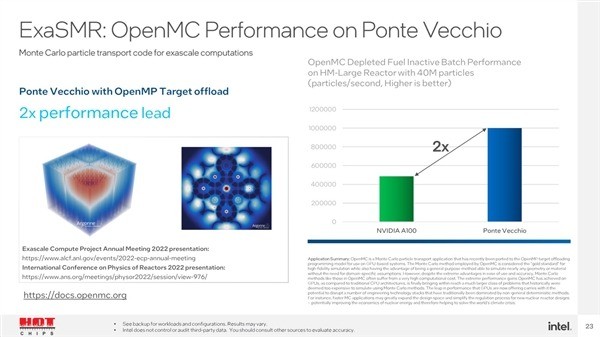
另外ExaSMROpenMC的计算性能可以领先2倍,NekRS领先0.3-1.7倍。
当然,英伟达新一代H100已经发布...
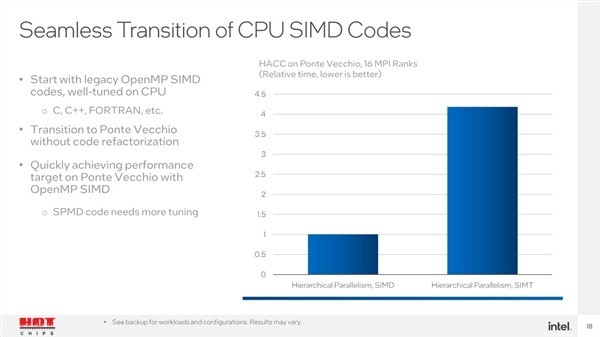
PonteVecchio的任务是为美国首批三台千万亿次超级计算机之一的Aorura结合下一代可扩展的XeonSapphireRapids。遗憾的是,SapphireRapids一再推迟,预计要到明年第二季度才能发布。达蓬特
Vecchio还没有大规模生产上市。
相比之下,AMD的三代骁龙处理器,本能
由MI250X加速卡组成的Frontier已经投入运行,以1.6EFlops的性能成为超算(开放)之王。